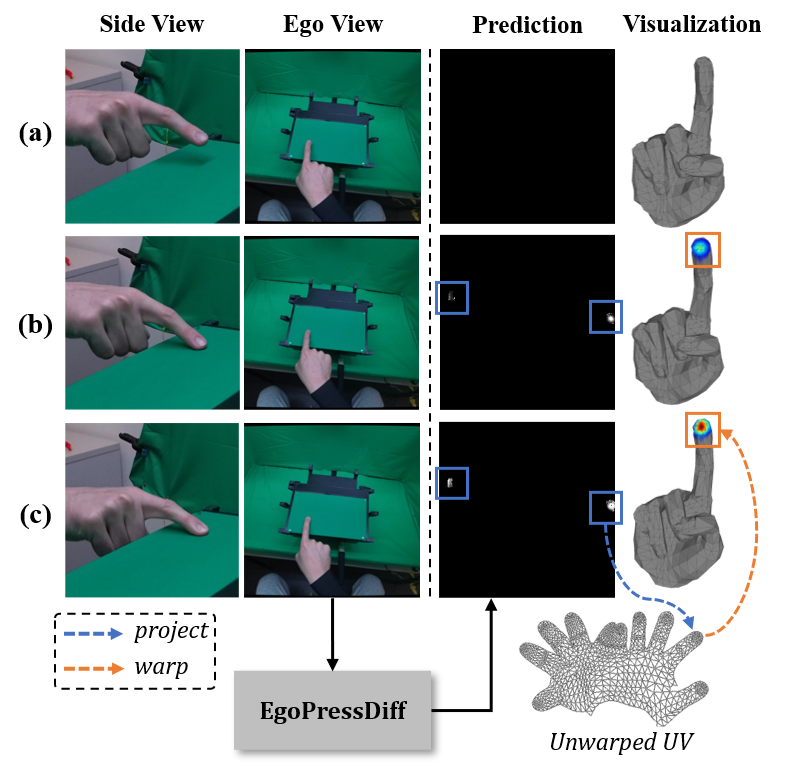
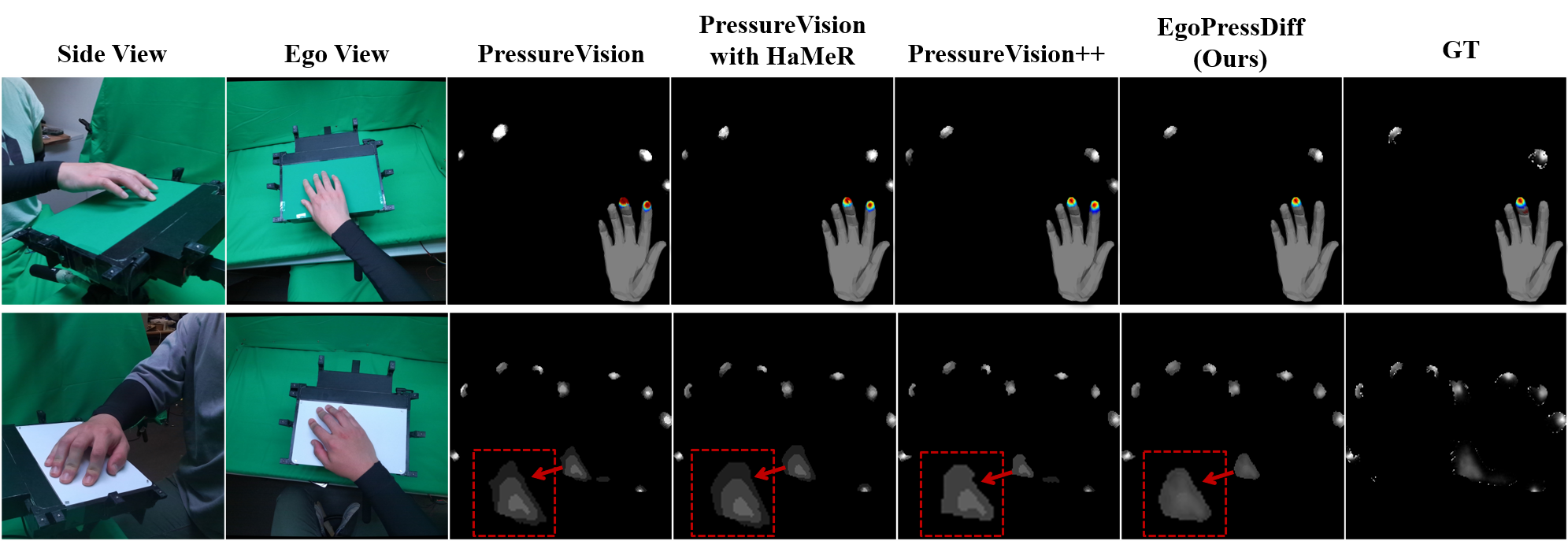
A. Network Architecture
The training pipeline of our method is illustrated in Figure 2 (a).
The network consists of several key components, including the PoseNet, Vertex Encoder, and Distribution-Calibrated (DC) Spatial Layer.
These modules work together to extract, fuse, and align multi-modal features.
First, PoseNet is employed to extract hand pose features, which are added to the input latent to explicitly enhance the model's awareness of the hand's posture.
Second, since depth information is critical for inferring hand contact with the environment,
we use VAE to encode the depth maps, projecting its features into the same feature space as input latents.
To further capture the hand's spatial structure,
we propose a Vertex Encoder that uses the 3D vertex coordinates of the MANO hand model as a geometric prior,
enabling the model to learn the correlation between 3D hand geometry and pressure. Furthermore, a CLIP image encoder processes the egocentric RGB frames.
The resulting image embeddings serve a dual purpose: they provide global visual context and, within the DC Spatial Layer,
calibrate the distribution of hand-vertex embeddings, ensuring distributional consistency across modalities.
In what follows, we will present the architectural details of these key components.
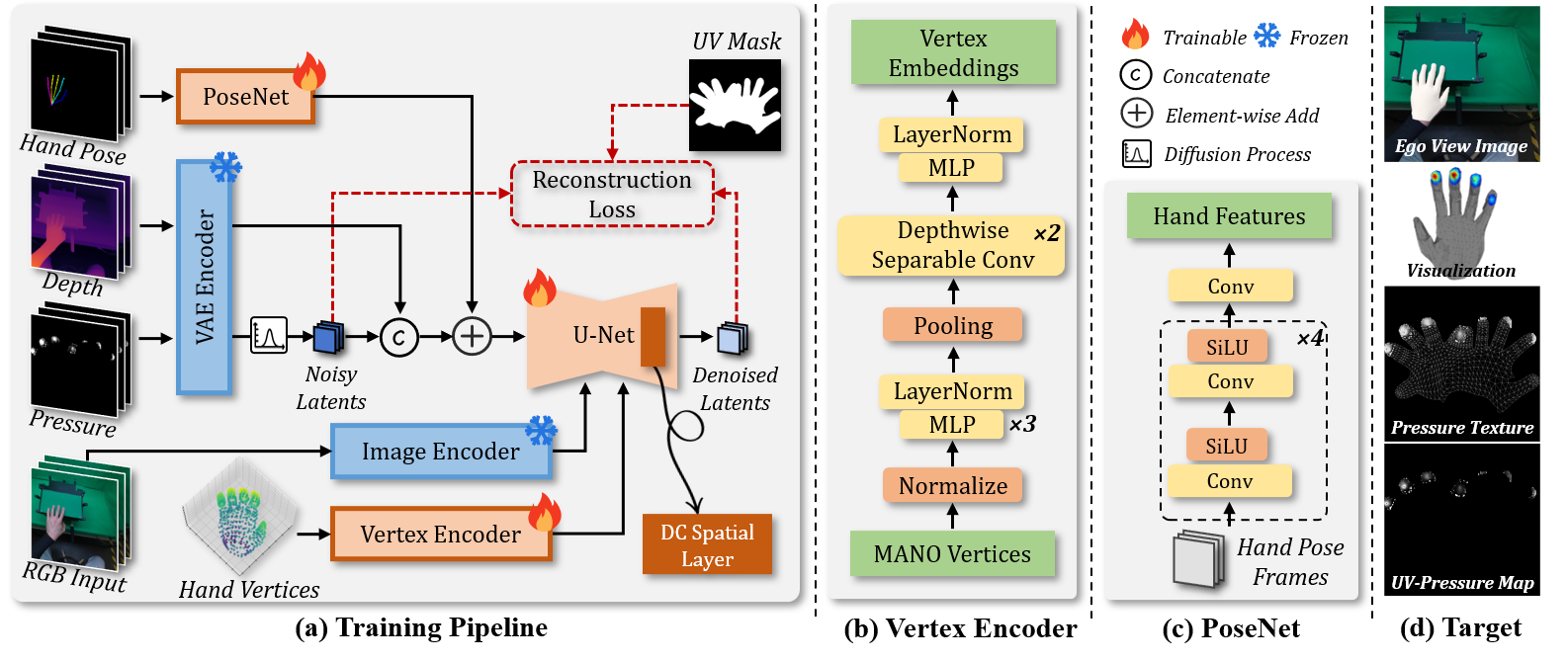
Figure 2: Overview of EgoPressDiff.
(a) The training pipeline of EgoPressDiff.
The model processes five input streams through dedicated encoders:
a PoseNet for hand pose, a VAE for depth and UV-pressure, a CLIP image encoder for RGB frames, and a Vertex Encoder for hand vertices.
To align features from the vertex and image embeddings, we introduce a DC Spatial Layer, which replaces the original spatial layer in the U-Net.
The pipeline is trained end-to-end using a reconstruction loss, with a UV mask employed to up-weight the hand UV pixels.
(b) The architecture of Vertex Encoder.
(c) The architecture of PoseNet.
(d) Visualization of the reconstruction target, from top to bottom: The input egocentric RGB image with 3D MANO hand mesh;
A 3D visualization of the ground-truth pressure on the hand surface; The pressure represented as a texture on the unwrapped UV layout;
The final 2D UV-pressure map, which serves as the reconstruction target.
(1) Vertex Encoder.
To extract a compact and coherent representation from MANO hand vertices, we propose a Vertex Encoder.
The input is a sequence of hand-mesh vertices with shape (B, N, 778, 3), where B, N, 778, and 3 correspond to batch size, number of frames, number of vertices, and (x,y,z) coordinates.
The encoder outputs a feature sequence of shape (B, N, 1024). As shown in Figure 2 (b), the process has three stages:
-
Spatial feature extraction: Each frame is normalized to remove global translation and scale.
A shared MLP maps the 3D coordinates to a higher-dimensional space, followed by symmetric max-pooling to form a frame-level embedding.
-
Temporal feature mixing: The embeddings are processed by depthwise-separable convolution blocks, capturing local temporal dynamics efficiently.
-
Projection: A linear layer with LayerNorm projects the features to the final 1024-dimensional representation.
This hierarchical design enables efficient distillation of MANO vertex data into structured features suitable for denoising models.
(2) PoseNet.
Many generative models integrate human pose features via ControlNet, but this adds significant computational cost.
We propose a lightweight PoseNet for extracting hand pose map features.
As shown in Figure 2 (c), PoseNet consists only of convolutional and SiLU layers.
For stable training, the network uses Gaussian weight initialization, and its final projection layer is a zero-initialized convolution.
(3) Distribution-Calibrated Spatial Layer.
To integrate multimodal control signals, we introduce the DC Spatial Layer.
As shown in Figure 3 (a), unlike a standard diffusion U-Net spatial layer that conditions features on text, our design uses dual branches for image and vertex embeddings.
Because these embeddings lie in different feature spaces, we add a calibration block to align them before fusion.
Let z be the latent input. After self-attention, z passes through two cross-attention blocks, yielding zimg and zvtx.
We compute their channel-wise mean and standard deviation:
(μimg, σimg) and (μvtx, σvtx).
We align them by enforcing:
\[
\frac{z^{img} - \mu_{img}}{\sigma_{img}} = \frac{z^{vtx} - \mu_{vtx}}{\sigma_{vtx}}
\]
From this, we derive the calibrated vertex latent:
\[
\bar{z}^{vtx} = \frac{z^{vtx} - \mu_{vtx}}{\sigma_{vtx}} \times \sigma_{img} + \mu_{img}
\]
Finally, the calibrated z̄vtx is fused with zimg via element-wise addition and passed to the next temporal layer.
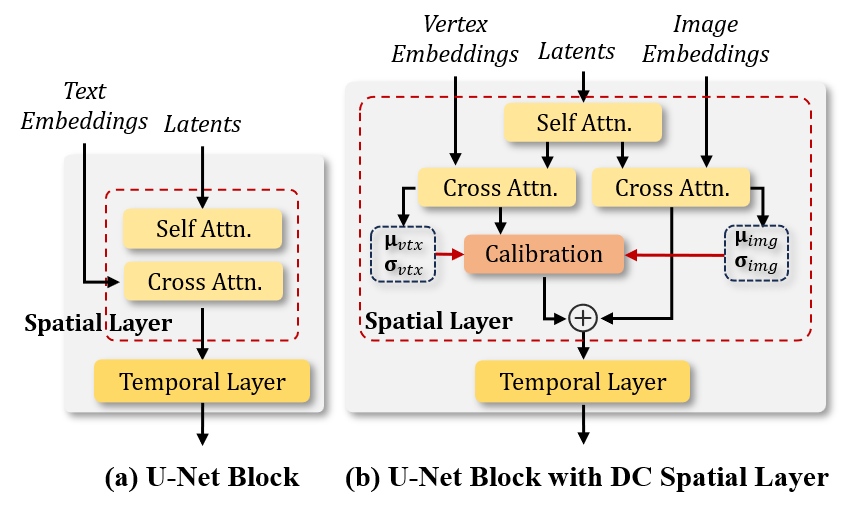
Figure 3: (a) The original U-Net block. (b) Our proposed Distribution-Calibrated (DC) Spatial Layer integrated into the U-Net block.
Here, μ and σ denote the mean and standard deviation, respectively.